
Are Intrinsic Activation Patterns Indicative of Memorization?
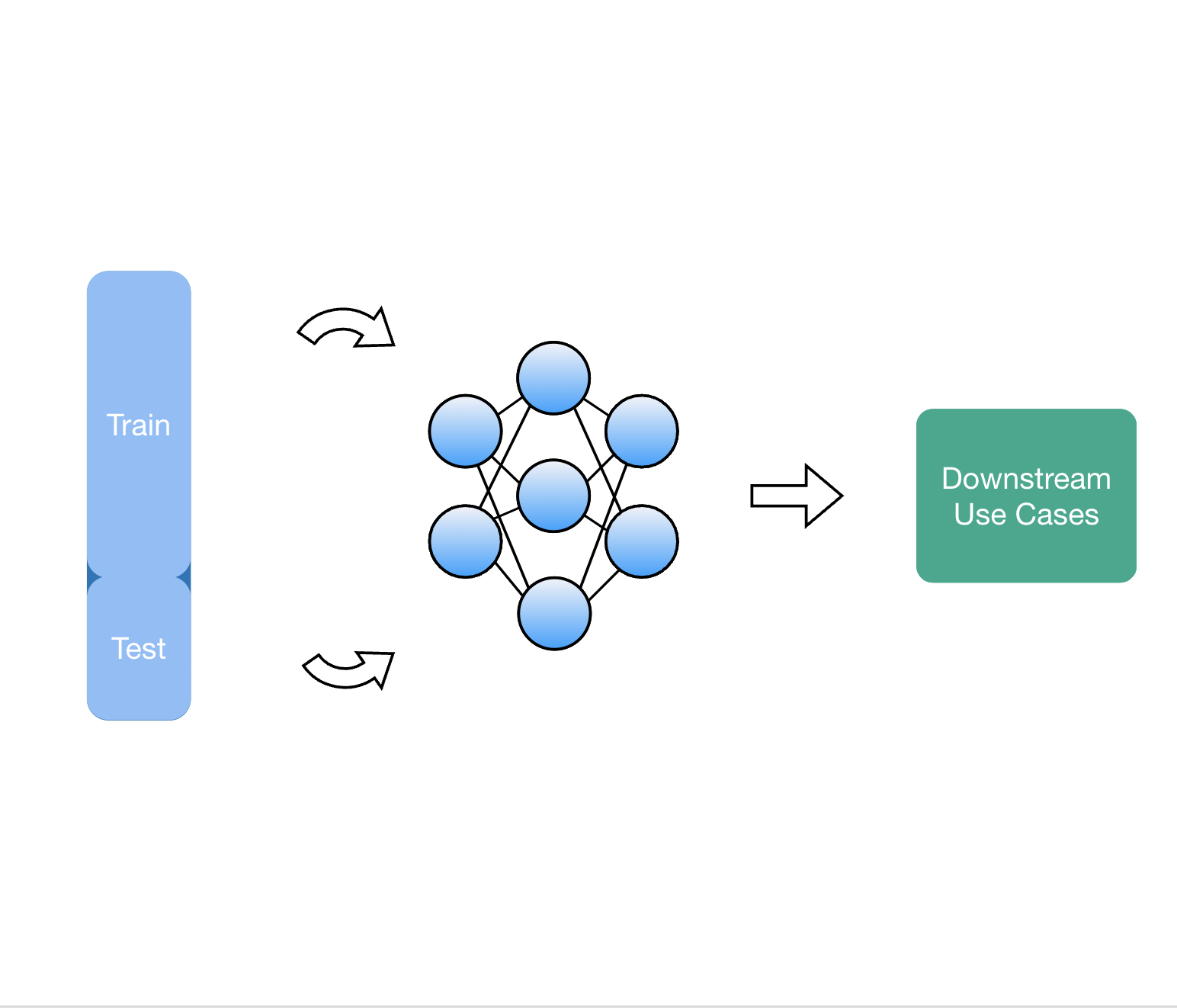
In this work, we posit that organization of information across internal activations of a network could be indicative of memorization. Consider a sample task of separating concentric circles, illustrated in the figure below. A two-layered feed-forward network can learn the circular decision boundary for this task. However, if the nature of this learning task is changed, the network may resort to memorization. When a spurious feature is introduced in this dataset such that its value (+/−) correlates to the label (0/1), the network memorizes the feature-to-label mapping, reflected in a uniform activation pattern across neurons. In our work we refer to this kind of model behaviour as heuristic memorization. In contrast, when labels for the original set are shuffled, the same network memorizes individual examples during training and shows a high amount of diversity in its activation patterns. This example demonstrates how memorizing behavior is observed through diversity in neuron activations. We refer to this form of memorization as example-level memorization.
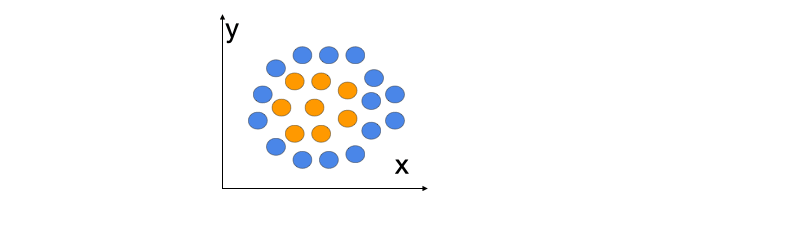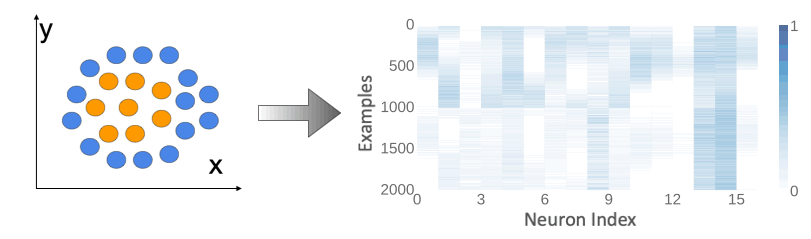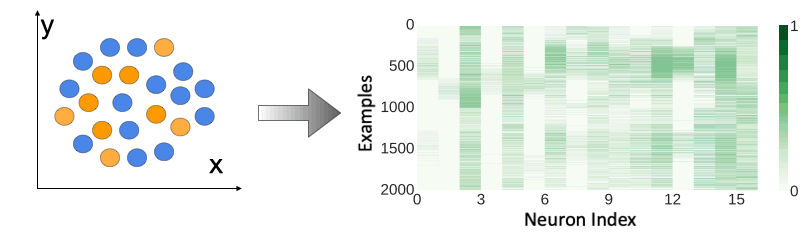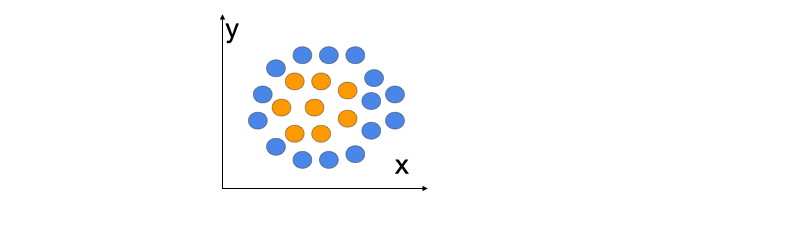
Why Intrinsic Evaluation?
The impetus to study ways to perform intrinsic evaluation of neural networks is multi-fold:
- The practical perspective. Generally, evaluating models for the afore-defined memorization requires researchers to laboriously collect specialized and labeled datasets to measure the extent of suspected fallacies in models. While these sets make it possible to assess model behavior over a chosen set of features, the larger remaining features remain hard to identify and study.
- The interpretability perspective. Performance measures over the evaluation sets that are generally used to assess model behaviour lack interpretability and are not indicative of internal workings that manifest certain model behaviors.
How do we Quantify Neuron Diversity?
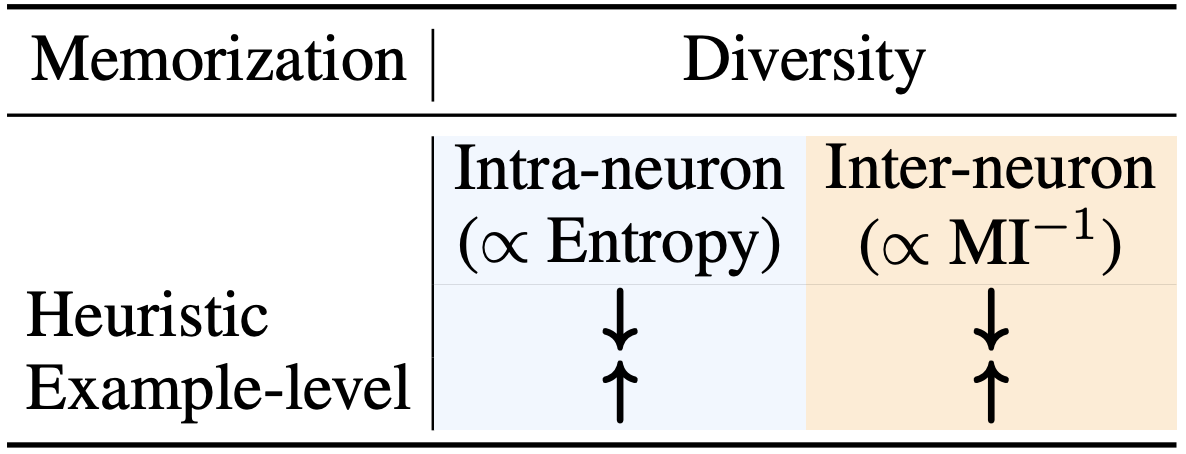
We formalize the notion of diversity across neuron activations through two measures: (i) intra-neuron diversity: the variation of activations for a neuron across a set of examples, and (ii) inter-neuron diversity: the dissimilarity between pairwise neuron activations on the same set of examples. We hypothesize that the nature of these quantities for two networks could point to underlying differences in their generalizing behavior. In order to quantify intra-neuron and inter-neuron diversity, we adopt the information-theoretic measures of entropy and mutual information (MI), respectively.
What did we find?
Heuristic Memorization
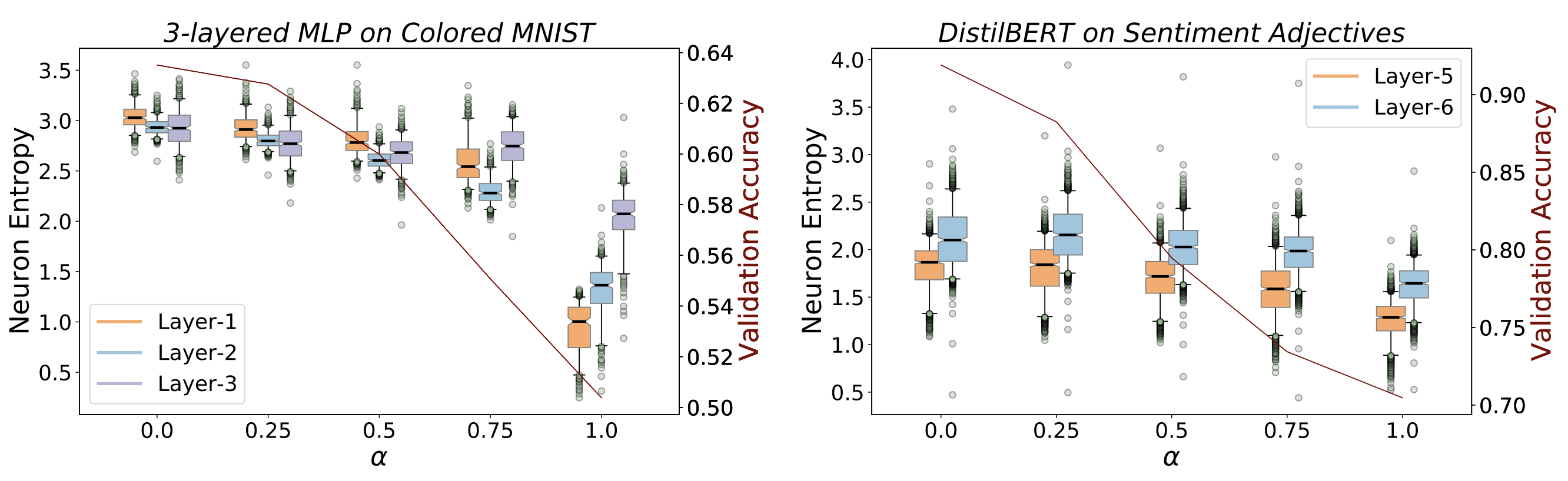
Through our experiments, we first note that low entropy across neural activations indicates heuristic memorization in networks. This is evident from the figure below, where we see that (1) as we increase α the validation performance decreases, indicating heuristic memorization (see the solid line in the plots); and (2) with an increase in this heuristic memorization, we see lower entropy across neural activations. We show the entropy values of neural activations for the 3 layers of an MLP trained on Colored MNIST (left sub-plot) and for the last two layers of DistilBERT on Sentiment Adjectives (right sub-plot). In both these two scenarios, we see a consistent drop in the entropy with increasing values of heurisitic memorization (α), with a particularly sharp decline when α = 1.0.
Furthermore, we observe that networks with higher heuristic memorization exhibit higher mutual information across pairs of neurons. In the figure below, networks with higher memorization (↑ α), have larger density of neurons in the high mutual information region. While this trend is consistent across the two settings, we see some qualitative differences: The memorizing (α = 1.0) MLP network on Colored MNIST (left) has a uniform distribution across the entire scale of MI values, while DistilBERT on Sentiment Adjectives (right) largely has a high-density peak for an MI of ∼ 0.9
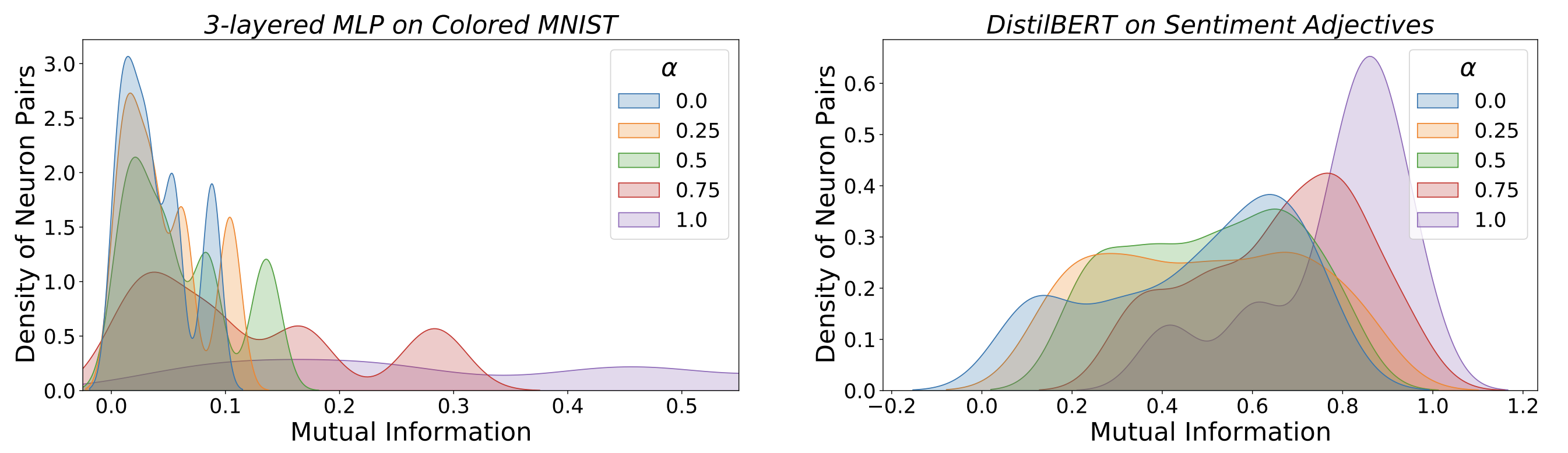
Example-level Memorization
We simulate example-level memorization through label shuffling on a variety of datasets. First, we note that model performance on the validation set decreases with increased label shuffling, validating an increase in example-level memorization (in the figure below). Interestingly, this dip in validation accuracy is accompanied with a consistent rise in entropy across the neurons. For MLP networks trained on MNIST (left), we see a distinct rise in entropy even with a small amount of label shuffling (β = 0.25), followed by a steady increase (layers 2 and 3) or no change (layer 1) in entropy. A dissimilar trend is seen for DistilBERT fine-tuned on IMDb (right): a distinct rise for high values of β and a consistent value for low or no label shuffling.
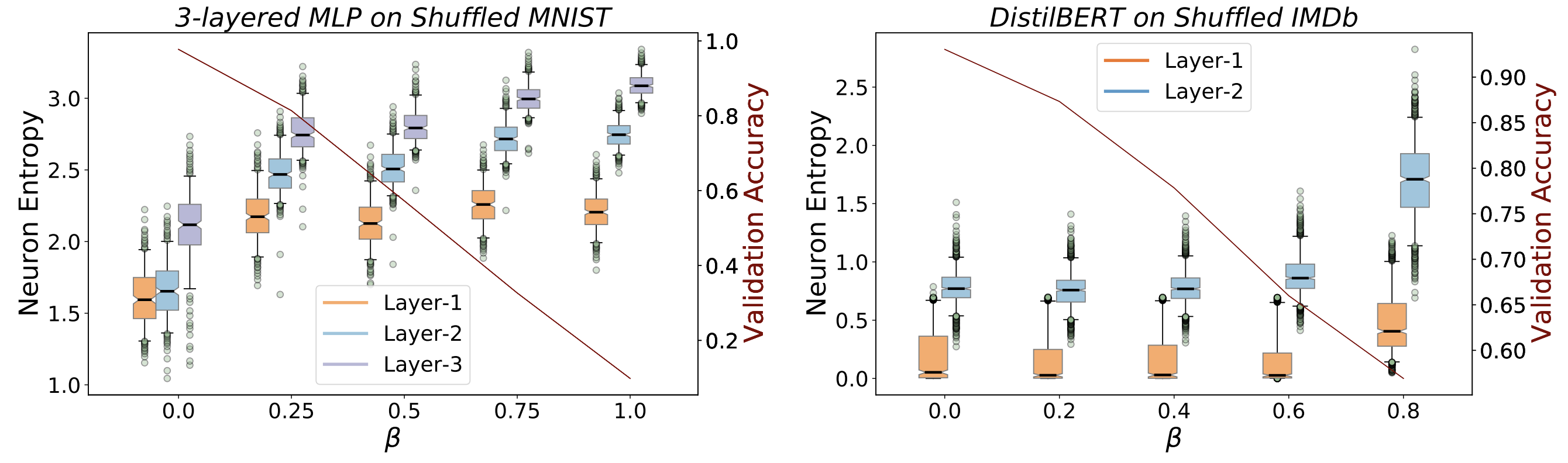
Our hypothesis for the relation between example-level memorization and MI is supported by the figure below. In both settings, networks trained on higher β values consist of neuron pairs that show low values of MI (left side of the plots). In line with the previous observations, we find that MLPs trained on some amount of label noise (any β > 0.00) on MNIST (left sub-plot) have a higher density of neuron pairs concentrated at low values of MI. Meanwhile, for DistilBERT on IMDb (right sub-plot), we observe that neuron pair density gradually shifts towards lower values of MI with increasing β.
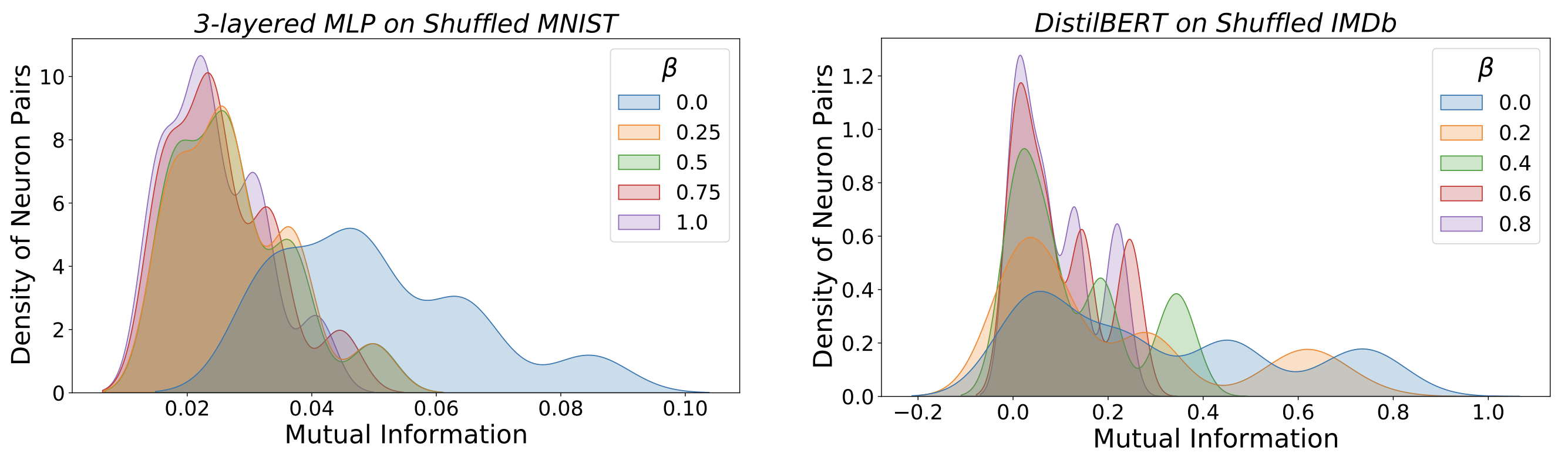
How to Cite
This work will be presented at NeurIPS 2022. It can be cited as follows.
bibliography
Rachit Bansal, Danish Pruthi, and Yonatan Belinkov. "Measures of Information Reflect Memrorization Patterns." Advances in Neural Information Processing Systems 35 (2022).
bibtex
@article{bansal2022measures,
title={Measures of Information Reflect Memrorization Patterns},
author={Rachit Bansal and Danish Pruthi and Yonatan Belinkov},
journal={Advances in Neural Information Processing Systems},
volume={35},
year={2022}
}